
System Design
Why most system failures are coupling failures
Most system failures originate from a mismatch between how components depend on each other over time and the communication model chosen to express that dependency.
You can swap protocols, add caching layers, and tune the underlying infrastructure, but if the temporal relationship between components is wrong, the system has the potential to fail in predictable ways.
Some of the most common failure modes are:
- Cascading outages when one service slows down
- Retries that amplify load under pressure
- Scaling bottlenecks that require architectural redesign, not just more hardware
- Evolution constraints that force coordinated deploys across unrelated teams
These are all symptoms of time coupling. It's the degree to which one component's progress depends on another being available, responsive, and correct at the same moment.
Before evaluating any technology, we have to answer one architectural question:
Does progress in one component depend on the immediate availability of another?
Your answer determines which failure modes you are buying, and which you are designing out.
System Design
Time Coupling as an Architectural Constraint
"Synchronous" and "asynchronous" are commonly used as adjectives for protocols. That framing is imprecise and produces poor decisions.
More accurately, they describe the temporal dependency relationship between a producer and a consumer:
- Synchronous: The producer blocks until the consumer responds. Both must be available simultaneously. Progress is coupled to responsiveness.
- Asynchronous: The producer emits and continues. The consumer processes independently. Temporal availability is decoupled.
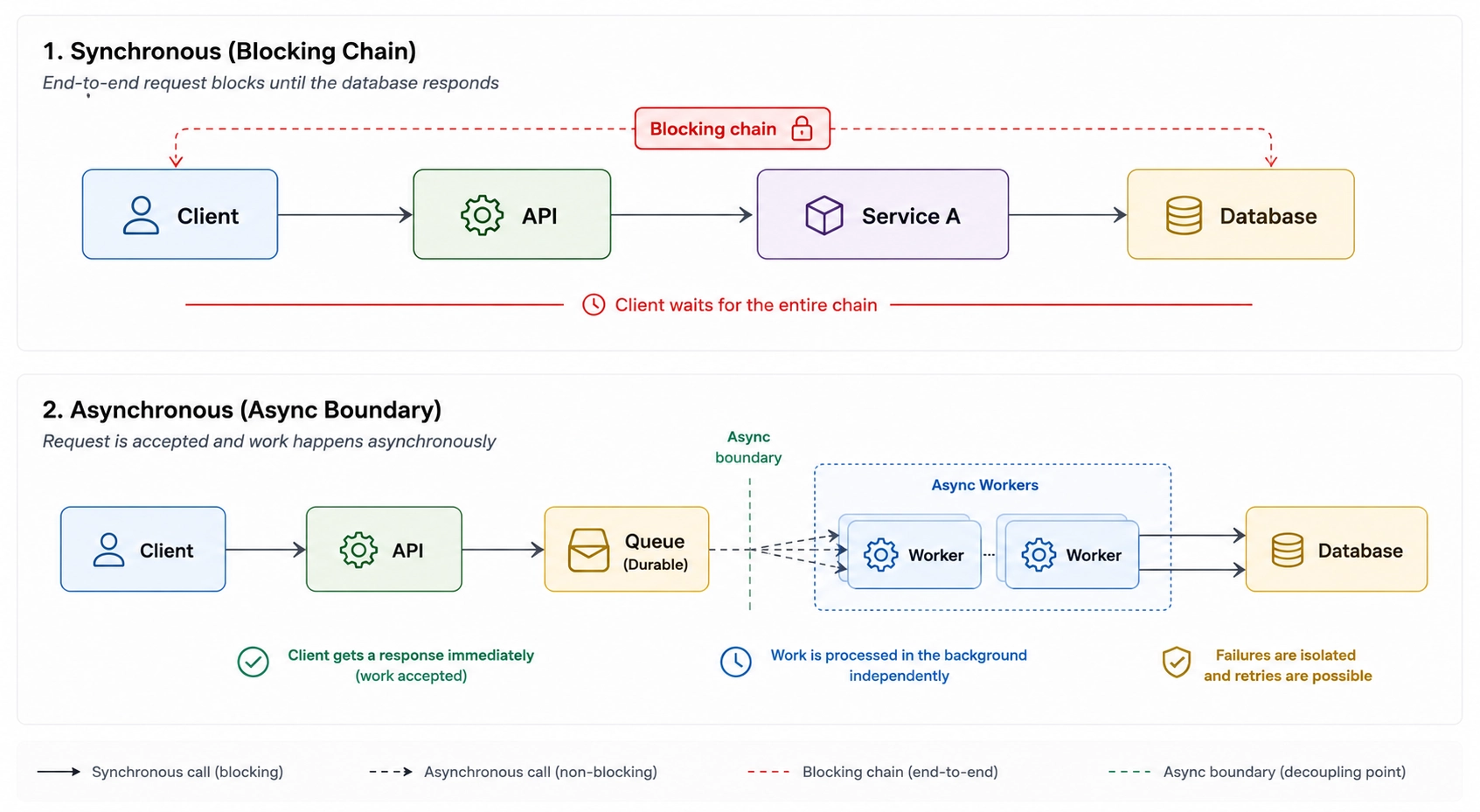
A service that calls a queue's API and waits for the enqueue acknowledgment before responding is still synchronously coupled. The HTTP endpoint that accepts a request, writes to a queue, and immediately returns 202 Accepted is behaving asynchronously from the client's perspective, regardless of what happens underneath.
Time decoupling alone doesn’t eliminate dependency. Systems that appear asynchronous can still fail under the same conditions. The next section examines how those failure modes appear in practice.
System Design
How coupling shapes failure behavior
Rather than cataloging what each protocol offers, it is more useful to understand what breaks when temporal coupling is misapplied. These are not hypothetical failure modes. They are the structural consequences of dependency behavior under load and failure. Let's look at them one by one.
Synchronous request chains
Primary failure mode: availability amplification.
Technically speaking, if Service B slows down or fails, Service A degrades or fails with it. In a chain of three services, each with 99.9% availability, the effective system availability compounds to approximately 99.7% unless fallback paths are defined. Add more hops and the math worsens predictably.
Availability loss, however, is often easier to detect than latency propagation. A P99 spike in any downstream service propagates upward through every synchronous caller. In a five-service chain, a 200ms outlier at the leaf becomes a compounding liability at the root - often before the system appears outright unhealthy.
Retry behavior under failure amplifies this further. When callers retry a degraded service, load increases precisely when the service has the least capacity to handle it. This is a retry storm: a structural consequence of tight coupling, not merely a flaw in the retry logic.
Synchronous communication gives you deterministic control flow, immediate consistency guarantees, and a simple mental model that maps directly to function-call semantics. These properties are real and valuable especially when the dependency is bounded, latency is predictable, and the result is required before proceeding.
Webhook systems and hidden delivery coupling
Primary failure mode: shifted coupling.
Webhooks appear asynchronous because the producer no longer waits for the work itself to complete. The request path returns immediately, and execution continues independently on the consumer side.
But consumer availability is still required at delivery time. If the consumer is unavailable when the event is emitted, delivery either fails or depends on the producer retrying later.
This hidden dependency is easy to underestimate because the architecture appears decoupled at the request layer. In practice, the reliability model is now owned by the producer's retry semantics instead of buffered infrastructure boundaries.
For third-party integrations such as payment events, CI triggers or identity providers this is often a reasonable trade-off. Across trust boundaries, webhooks provide low-friction event notification without requiring shared infrastructure.
For internal service communication, however, the pattern becomes fragile quickly. Delivery guarantees are difficult to standardize, retry behavior becomes inconsistent across producers, and failure visibility degrades over time.
What webhooks do provide effectively is inversion of control, elimination of polling overhead, and lightweight event notification across independently operated systems.
Brokered async and eventual consistency
Primary failure mode: latent inconsistency and consumer lag.
The broker decouples producer and consumer lifecycles, which isolates synchronous availability propagation more effectively. Producers no longer need consumers to be immediately reachable, and transient failures no longer trigger the same retry amplification patterns seen in synchronous request chains.
A different class of system behavior now emerges:
- Latent inconsistency: The system is eventually consistent. Between event emission and consumer processing, the system exists in a transitional state. Any caller that assumes immediate propagation will make incorrect decisions.
- Consumer lag: Under sustained load, consumers can fall behind producers. Queue depth growth is a deferred failure that is invisible in observability dashboards until it becomes critical.
- Dead letter accumulation: Malformed, poisoned, or unprocessable messages accumulate silently unless explicitly monitored and handled. A dead letter queue without alerting is a reliability gap masquerading as a safety net.
The operational cost of brokered async is often underestimated. Distributed tracing becomes required discipline. Dead letter queues require monitoring and runbooks. Consumer lag must be tracked as a first-class health metric alongside latency and error rate.
These failure modes rarely appear in isolation. Most production systems combine coupling models at different boundaries.
System Design
Hybrid boundary patterns in real systems
Pure synchronous or pure asynchronous architectures are uncommon in production. Most systems are hybrid: synchronous at the edge, asynchronous in the interior.
This is a response to competing system constraints that cannot be satisfied simultaneously by a single coupling model:
- UX requirement: The client needs an immediate acknowledgment to confirm that intent was received and accepted.
- System requirement: The work that follows cannot be bound to a single request-response window without creating cascading reliability and scaling liabilities.
The standard resolution is to accept synchronously, process asynchronously:
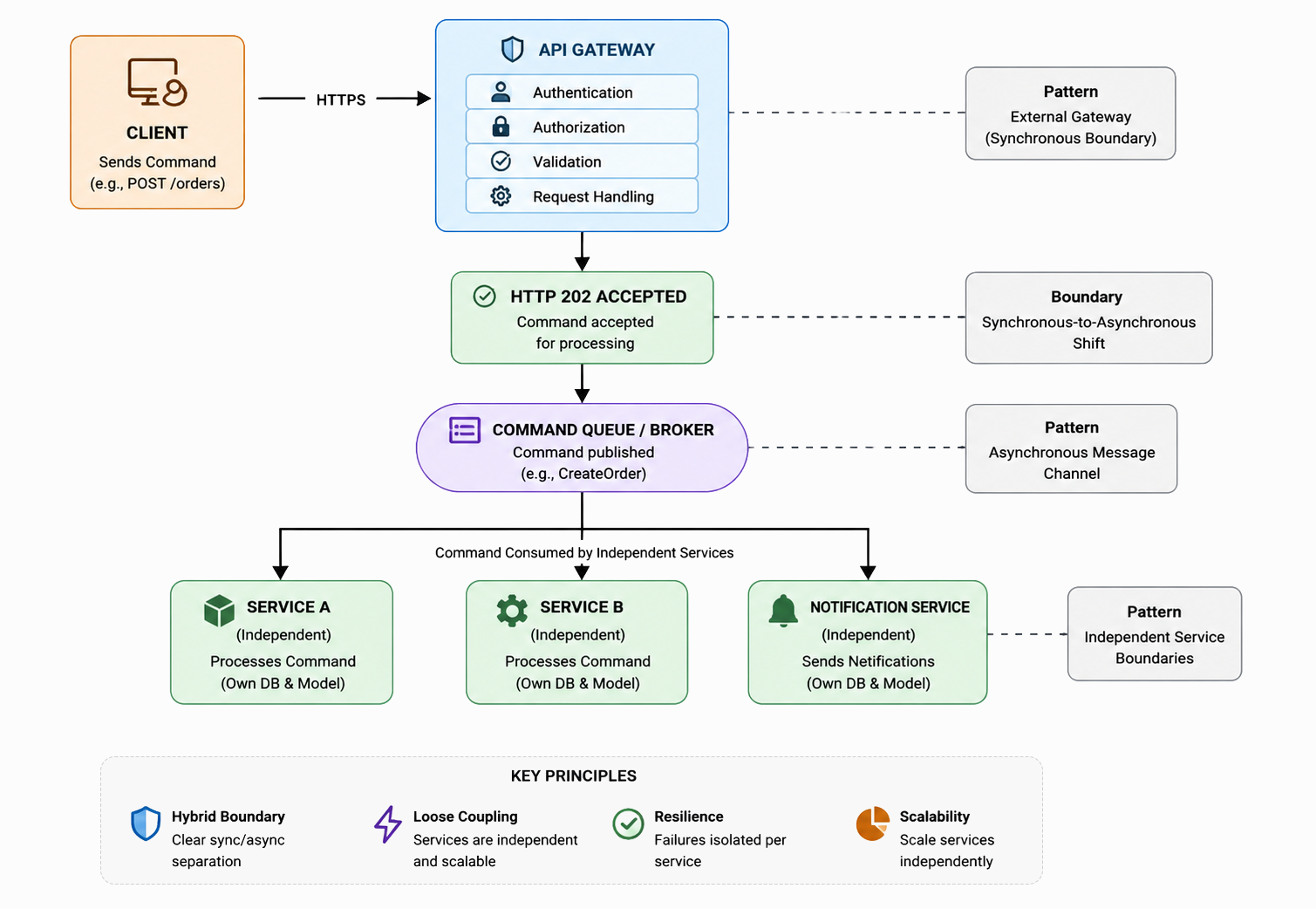
The sync boundary sits at the edge acknowledgment. Everything after it can now scale, fail, and retry independently of the client request lifecycle.
Anti-patterns to recognize
Synchronous fan-out. The API layer calls multiple downstream services before responding. Response time is now the sum of all downstream P99s. Failure in any one propagates upward.
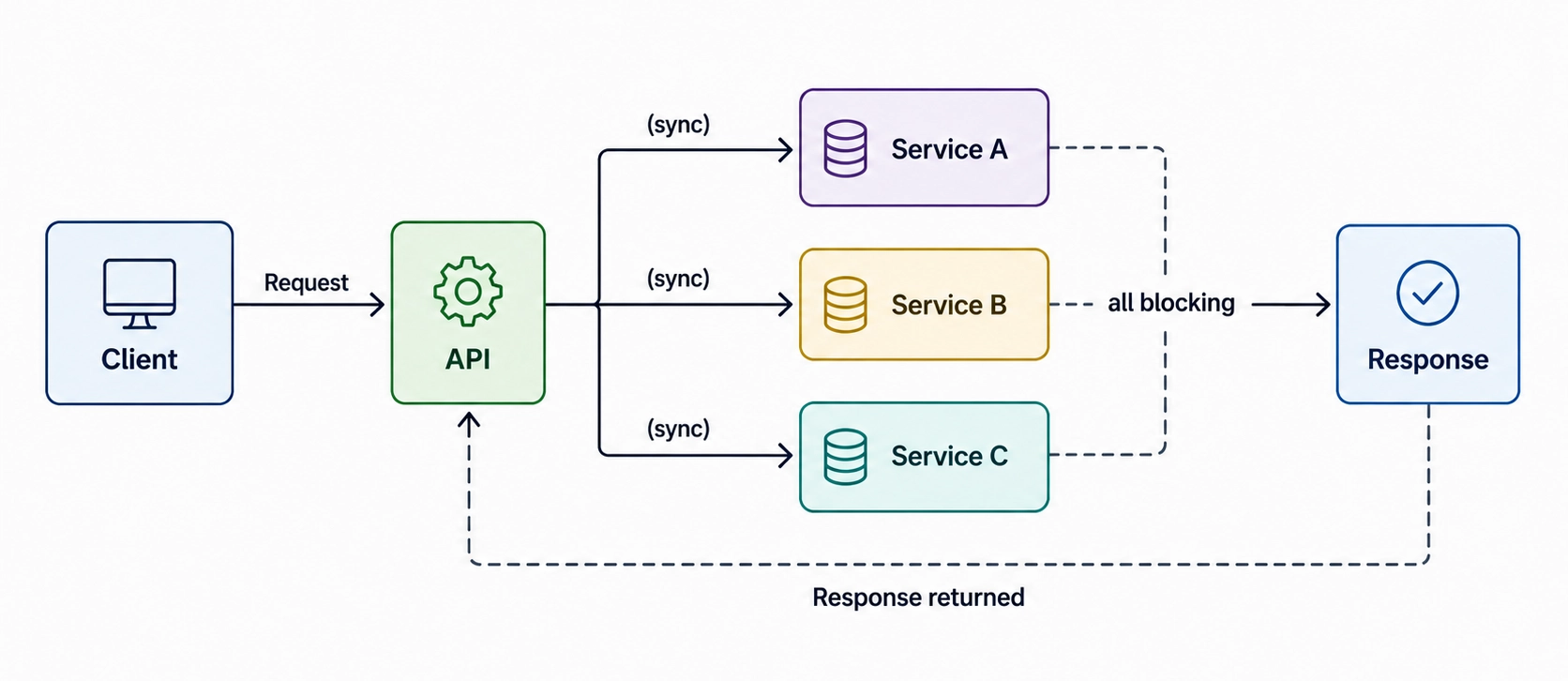
This is the most common anti-pattern. It typically starts with two services and grows through accretion.
Fire-and-forget without durability occurs when messages are emitted without durable persistence or acknowledgement guarantees. The operation appears async but silently drops messages under failure conditions. The architecture claims decoupling. The implementation accepts loss.
Premature async. It happens when you introduce a queue for a single-consumer, low-latency operation. The operational overhead including dead letter handling, consumer monitoring, distributed tracing is not offset by any architectural benefit. Asynchronous boundaries should exist because they remove structural constraint, not because queues are fashionable.
Where to place the async boundary
Use this boundary checklist before introducing async:
- What counts as request completion? Is an immediate acknowledgment sufficient, or does the caller require the business outcome before it can proceed?
- Can correctness tolerate deferral? If the work is processed seconds or minutes later, will any invariants, SLAs, or user expectations be violated?
- How will completion be observed? How will downstream systems and the UI know async work has finished (polling, webhook, push, status read model)
- Are ordering constraints explicit? Must event A complete before event B, and if so, where is that ordering guaranteed?
- Is queue acceptance a safe handoff point? Can the request be considered successful once the message is durably written to the broker?
- Are retries and duplicates safe? If processing happens more than once, is the operation idempotent and are side effects protected?
If questions 1-2 require immediate outcome coupling, keep the boundary synchronous at that step. If questions 3-6 are answered with durable handoff and operational clarity, push the boundary earlier and process asynchronously behind it.
The most common architectural mistake: defaulting to synchronous across the entire call graph, then patching brittleness with retries. Retries manage transient failures. They do not fix structural coupling. If retries are your primary resilience mechanism for a critical path, the coupling model is wrong.
System Design
Decision lens: evaluating time coupling
This checklist can be used to classify a communication boundary before selecting any technology.
Execution dependency
- Does the caller require the result before it can proceed?
- Is the dependency part of the critical request path?
- Can the work be deferred without breaking correctness?
Latency sensitivity
- Is the latency predictable under load?
- What happens to the caller when the dependency becomes slow rather than unavailable?
- Is tail latency acceptable on this path?
Availability impact
- If the dependency fails completely, does the caller fail with it?
- Is degraded operation acceptable, or must the workflow halt?
- How much availability loss compounds across the chain?
Consistency requirement
- Is immediate consistency required?
- Can the system tolerate temporary divergence?
- What is the acceptable delay before correctness must converge?
Failure handling:
- How are retries controlled under degradation?
- What prevents retry amplification or cascading load?
- Where does backpressure accumulate?
Operational reality
- Does this dependency require coordinated scaling?
- Will this interaction become fan-out over time?
- Are you optimizing for immediate response or system resilience?
Patterns in the answers matter more than any single response. The goal is not to score the system, but to expose where correctness depends on immediate availability.
If most answers require immediate availability, bounded latency, and synchronous correctness, tight temporal coupling may be justified. And if the dependency can tolerate deferred execution, independent scaling, or eventual correctness, an asynchronous boundary is likely the safer architecture.
Technology selection follows dependency design
The mistake most teams make is treating the choice between "use an API" and "use a queue" as a technology preference. It is an architectural commitment with a specific failure model attached.
The correct sequence is:
- Identify where immediate availability is required
- Determine whether correctness depends on synchronous completion
- Understand which failure modes that dependency introduces
- Then choose the communication model that matches those constraints
The paradigm encodes the trade-off. The technology is how you deploy it.
System Design
How communication patterns behave under time dependency
The map below visualizes how common communication patterns behave under different levels of temporal dependency.
These are not strict categories or fixed coordinates. Real systems shift depending on topology, retry semantics, buffering strategy, deployment boundaries, and operational guarantees. The goal is not to classify protocols precisely, but to understand how dependency behavior changes across communication styles.
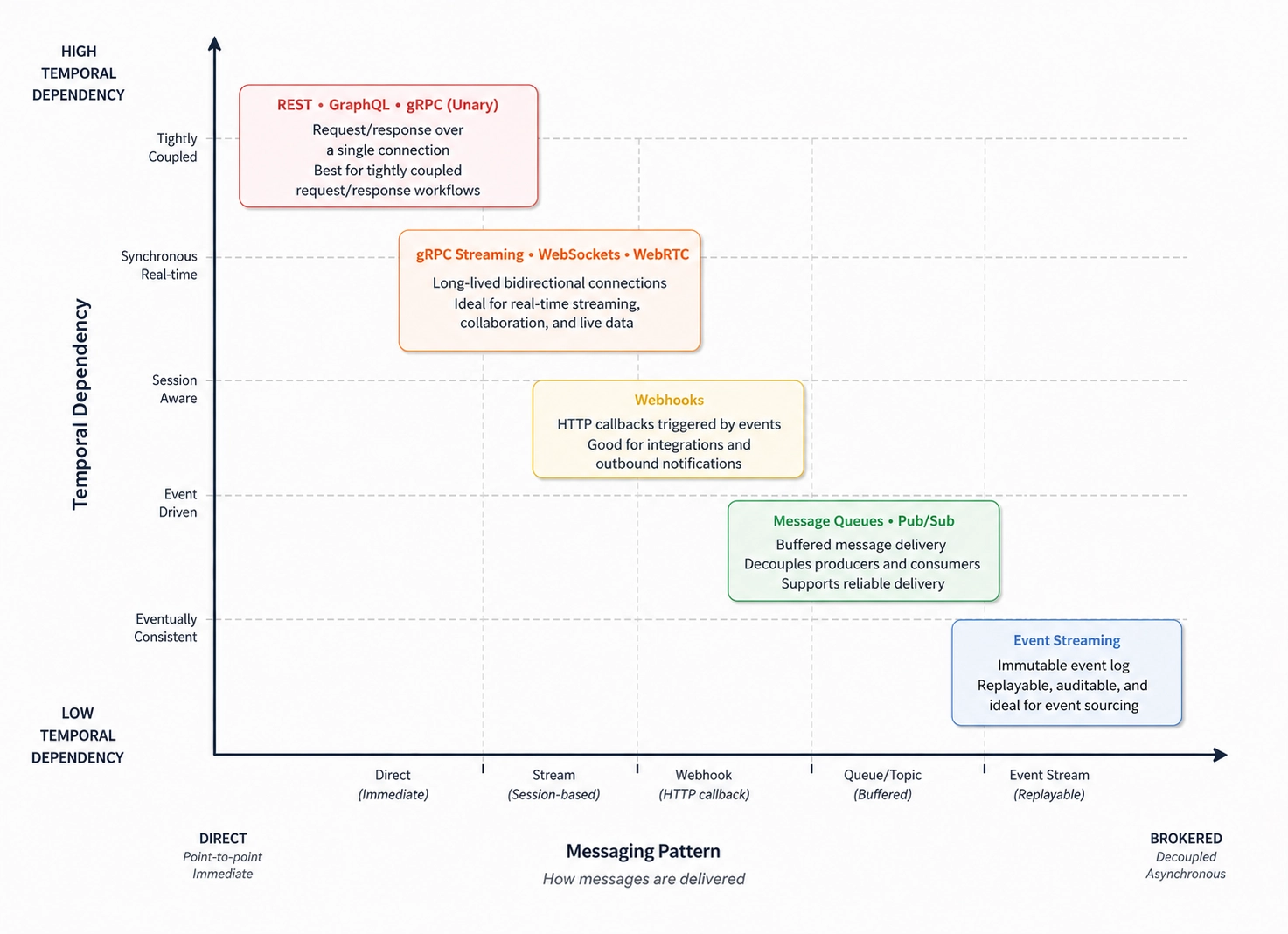
Key observations:
- REST, GraphQL, and gRPC (unary) tend to behave similarly from a time-coupling perspective. All three rely on synchronous request completion, which means latency, availability, and backpressure propagate directly through the call chain. Their meaningful differences are usually about contract design, payload efficiency, and interaction ergonomics.
- gRPC Streaming, WebSockets, and WebRTC reduce per-message overhead by maintaining long-lived connections. This lowers request overhead, but both sides must still remain co-present for the session to function. The coupling shifts from individual requests to session continuity. A stalled or disconnected peer still interrupts progress.
- Webhooks loosen request-time dependency, but they do not fully eliminate delivery-time dependency. The producer no longer blocks waiting for work to complete, yet successful delivery still depends on the consumer eventually becoming reachable. Retry strategy becomes part of the reliability contract.
- Message Queues and Pub/Sub systems introduce buffered communication boundaries. Producers and consumers no longer need to share the same execution window, which isolates latency spikes and availability failures more effectively. The trade-off shifts toward eventual consistency, consumer lag, retry handling, and operational observability.
- Event Streaming systems push this model further by treating communication as an append-only log rather than transient message delivery. Replayability, retention, and independent consumer progress become core architectural properties. At this point, the system is no longer optimizing primarily for immediate coordination, but for decoupled state propagation over time.
System Design
What this model does not explain
Time coupling explains when systems depend on each other.
It does not explain the shape of the interaction itself — whether communication is:
- discrete or continuous,
- bounded or long-lived,
- request-driven or stream-oriented.
Many architectural problems attributed to synchronous vs asynchronous communication are actually interaction-shape mismatches.
A WebSocket connection used like request/response is a shape mismatch. A long-running batch workflow forced into a single HTTP timeout window is also a shape mismatch. In both cases, replacing the transport or introducing a queue treats the symptom rather than the structural issue.
Time coupling is only one dimension of communication behavior. Interaction shape introduces a different set of constraints, trade-offs, and failure modes entirely.
System Design
Make time an explicit design decision
Every communication boundary encodes a temporal assumption.
It determines whether another component must be available immediately, eventually, or not at all within the same execution window. Most architectural discussions focus on protocols, transports, or tooling. The deeper decision is whether progress in one part of the system depends on another being responsive at the same moment.
That dependency model shapes how the system behaves under latency, load, partial failure, and change.
Synchronous communication works well when correctness depends on immediate coordination. It provides deterministic control flow, immediate feedback, and simpler reasoning around consistency. The trade-off is that latency, availability failure, and backpressure propagate directly through the dependency chain.
Asynchronous communication changes those failure dynamics. Buffered boundaries isolate producers from consumers, absorb transient disruption, and allow systems to scale and evolve more independently. The trade-off shifts elsewhere: eventual consistency, consumer lag, retry handling, duplicate delivery, ordering guarantees, and operational complexity become part of the architecture.
Neither model is universally better. Each encodes a different set of assumptions about how work progresses through the system and how failure is allowed to spread.
Before choosing REST, gRPC, webhooks, queues, or event streams, make the temporal dependency explicit.
If the system cannot proceed without an immediate result, keep the dependency synchronous and bound it carefully. If work can be deferred safely, introduce a durable asynchronous boundary and operate it intentionally.
The real architectural question is not "API or queue?"
It is: when must this dependency be true?